画像と類似度を一覧表示したい
本稿は、仕事をする上で「画像の似ている/似ていないを定量的に表現してみる」必要があり、画像の類似度と対象とした画像や類似度を一覧表示させる方法を少しだけ学んだので、忘れないうちに、そして更に勉強をするために、これまで学んだ内容を紹介する記事です。
コサイン類似度(Cosine Similarity)
言葉でも画像でも、その基準と対象物の類似度を数値化してみる手法として大した前提知識無しに理解し易いのはコサイン類似度ではなかろうかと思います。定義はこうです。
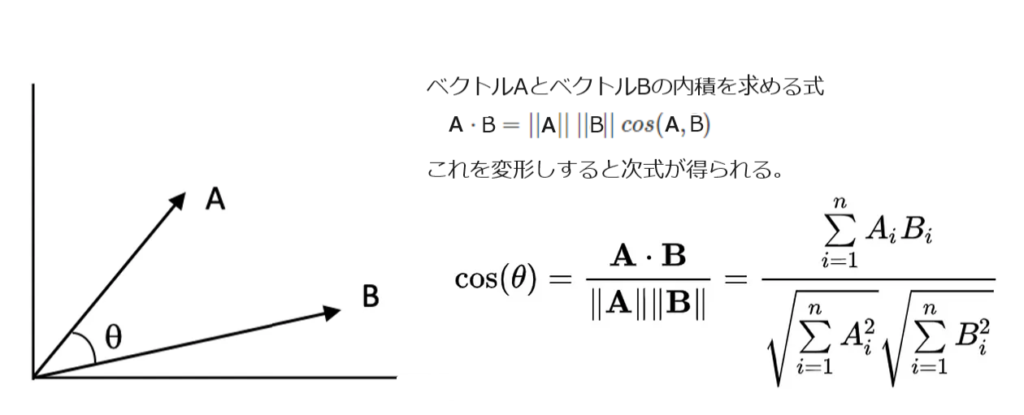
さて、もうちょっと直感的に理解しましょう。以下の図を見たときに、基準Aと似ている絵(ベクトル)はどれかと言われたら大きさが違うけれどもDだと答える人が大半だと思います。我々はどこに着目しているかというと、「向き(角度)」ですよね。Bは真逆ですし、Cは無関心な感じがします。よく会社組織なんかで「ベクトルを合わせて」とか「Oneなんとか」というフレーズを耳にしますが、本来は使命や目的は同じはずの会社組織内なのに、個々や部署が好き勝手に目標設定したりするものだからベクトルが合わないことが当たり前になっているので、わざわざこんなスローガンが打ち出されるわけです。(成果に焦るの役員とか高位管理職のせいです。)話が脱線しまいました。比較するベクトル間の角度が0に近ければ類似度は高く(1に近づく)、角度が-180°に近ければ類似度は低く(-1に近づく)なります。それを計算するのが上式です。

教科書で見慣れた2次元のベクトルは、x座標の値がいくつ、y座標の値がいくつとして表現されます。たとえば、以下のような具合に。
ベクトルA(x、y)=(3,8)
ベクトルB(x、y)=(4,6)
ベクトルC(x、y)=(-4,3)
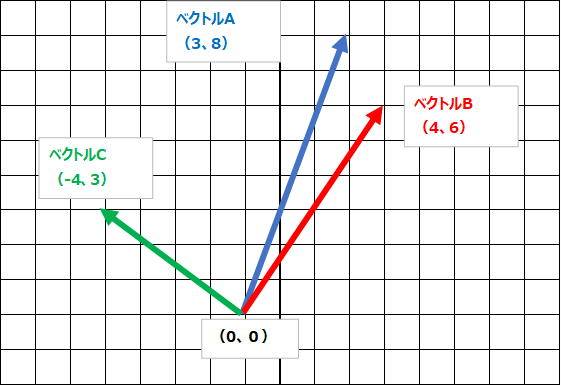
ちなみに、ベクトルAを基準として、ベクトルBとベクトルCはどちらがベクトルAに似ているでしょうか。コサイン類似度を計算するまでもなく、ベクトルBがベクトルAに似ていますが、一応計算するとこうなります。(Pythonの計算例です。)
import numpy as np
import cv2
import matplotlib.pyplot as plt
from google.colab.patches import cv2_imshow
# データ作成
A = [3, 8]
B = [4, 6]
C = [-4, 3]
# コサイン類似度を計算
cos_ab = np.dot(A, B)/(np.sqrt(np.dot(A, A))*np.sqrt(np.dot(B, B)))
cos_ac = np.dot(A, C)/(np.sqrt(np.dot(A, A))*np.sqrt(np.dot(C, C)))
print(cos_ab)
print(cos_ac)
output
0.9738412097417933
0.28089875327071334
ベクトルAとBのコサイン類似度は0.97くらいで、ベクトルAとCのコサイン類似度は0.28くらいになります。
画像をベクトル化
さて、何かの特徴や言葉や画像がベクトル化が可能なのかということですが、何でもベクトルで表現できます。画像をベクトル化してみましょう。
白黒画像(輝度は256階調で、白が255、黒が0とします。)である左の丸い画像は、画素値(=輝度値)で表現すると右の図のようになります。
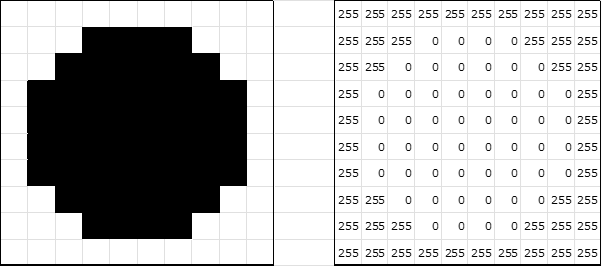
これを左上端からラスタスキャンしてカンマで数字を区切ると以下のようになります。
Sample image = [255,255,255,255,255,255,255,255,255,255255,255,255,0,0,0,0,255,255,255 255,255,0,0,0,0,0,0,255,255 255,0,0,0,0,0,0,0,0,255 255,0,0,0,0,0,0,0,0,255 255,0,0,0,0,0,0,0,0,255 255,0,0,0,0,0,0,0,0,255 255,255,0,0,0,0,0,0,255,255 255,255,255,0,0,0,0,255,255,255 255,255,255,255,255,255,255,255,255,255]
この画像は、10×10の複数次元配列ですが、上記のようにフラットな1次元配列(中身は、100(=10×10)次元ベクトル)に平坦化することがポイントです。
こうすれば、画像をベクトルとして扱い上述のようにコサイン類似度を容易に計算できます。
Pythonでは、画像データをndarrayの形で持ち、それをndarayのメソッドであるrevel()かflatten()で一次元配列化するのが簡単です。
MNISTデータで試す
機械学習を紹介する本やWebで必ず登場する手書き文字データセットを使って、(本来の使い方と違いますが)類似度を計算してみましょう。先の例のようにPythonを用います。
KerasのデータセットをPythonの開発環境にインストールしてれば、以下のコードで画像をインポートしてロードすることができきます。
from keras.datasets import mnist
(X_train, Y_train), (X_test, y_test) = mnist.load_data()X_trainには、28×28サイズの手書き文字の画像データが6000個格納されます。
Y_trainには、その画像の数字が何であるかの正解値が6000個格納されます。これらを使って機械学習させるのが本来の使い方ですが、0から9の手書きの画像がたくさんありますので、どれか数字を基準に決めて他の数字の画像との類似度を計算するのに、これらの画像データを使ってみることにしました。
6000個もの画像を扱う必要な無いし重いので、20個程度読み込みました。画像データは28×28サイズ、輝度値は0から255の範囲のndarayとなっています。これをOpenCVのcv2.imwriteを使ってPNGデータに変換して保存します。そうしてあるフォルダ内のPNGデータを読み込み、先頭のファイルを基準として他の画像とのコサイン類似度を計算しました。その結果がこちらです。

先頭の0行の画像が基準とした画像(数字の2が見えます)で、他の画像(1行から3行:数字の2と8と6)との類似度を計算しています。コサイン類似度以外の指標も載せています。
さて、お気づきでしょうか。基準画像である0行目の「2」と比較している他方の「2」は実はMNISTのオリジナルデータはなく、基準の「2」から作った画像で、右に2ピクセル、下に2ピクセルずらした画像なので、人間の感覚ではそっくりな画像ということになるのですが、コサイン類似度の値はどうでしょう。下の行の「8」よりも低いですね。「6」よりは高いですが、なんとも人間の感覚とは異なります。なるほど、だから、いろんな手書きの画像の教師データを用意して教え込むことで、文字認識の精度を上げていく機械学習が注目されるのですね。
画像と類似度の一覧表を作る
類似度が想像と違う値を示すのは脇に置いて、一覧表示にしましょう。html化するのとExcelファイル化するのを試しました。どちらも、pandasのDataFrameの形式で一覧表を作ることができます。
・html化は、DataFrame形式のデータから、to_htmlメソッドを使います。
・Excel化は、DataFrame形式のデータから、to_excelメソッドを使います。
画像の貼り付けは、htmlの場合は、以下の例のように画像へのパスをimg srcタグに展開する処理を行い、その後html化されることで実現します。
df["File path"].map(lambda s: "<img src='{}' width='200' />".format(s))
Excelの場合は、openpyxlライブラリのメソッドを使って、画像の貼り付けやセルの幅の設定などを行うことができます。VBAライクな操作になります。
コサイン類似度以外の類似度の指標
より人間の感覚に近いとされるSSIMとPSNRを使ってみましたが中身を理解できていません。(笑)
OpenCVの関数を用いました。
・quality.QualityPSNR_compute(対象画像、基準画像)
・quality.QualitySSIM_compute(対象画像、基準画像)
これらの関数は、「opencv-python」でOpenCVをインストールした場合では関数が見つからず、「opencv-contrib-python」でOpenCVをインストールすると見つかりました。以前は「opencv-python」でインストールしたOpenCVでもこれらの関数があったそうですが、いつのバージョンまでなのかは調べられませんでした。
添付ソースコードの処理の概要
上記添付のソースコードの概要を示します。
・リストを用意し、画像へのパスや類似度を格納する箱を作る。
・画像が格納されたフォルダを指定して画像へのパスリストを作る。
・類似度を計算する。(最初に読み込まれた画像を基準として他の画像との類似度を計算しました。)
・リストに画像へのパスや類似度データを追加していく。
・リストからDataFrameを作成する。
・DataFrameから、htmlやExcelファイルを作る。
注意:基準の画像と他の画像を別のDataFrameで作成したので、見づらいコードになっています。
もともと扱おうとしていた画像だとどうなるか
血液検査に特化したフローサイトメトリー法を用いた測定機器で得られた、ある測定チャンネルの画像を試しに、MNIST画像と同じように類似度を計算していきます。その測定機器が出力する測定結果に2次元のドットプロットがあります。機器の日常点検に用いる試料を測定した場合、この画像データは測定機器が正しく動作していれば人間の目にはわかりにくいくらいの変動しかありません。何かしらの原因で測定機器に問題がある、あるいは測定した試料(コンディションや取り扱い起因)に問題がある場合、この測定結果である画像が普段と異なるわけですが、その様子を定量的に示せないか、そんな動機で類似度を勉強していたのでした。
さて、やってみましょう。
先頭の行の画像が基準です。3行目の画像は基準の画像とも他の画像とも見た目に少し異なりますよね。(x方向に太い)類似度を見ると3つの指標とも他より小さい数値を示しています。
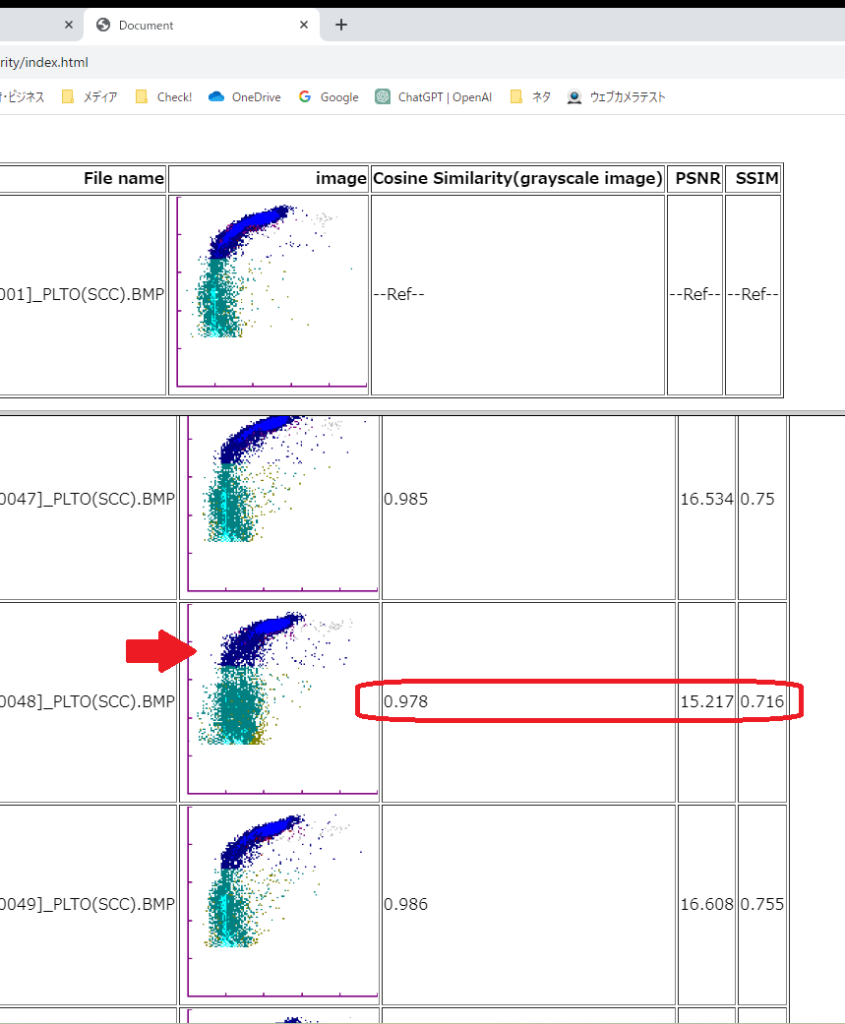
こんな感じで、異常判定に使える指標が無いか探索しています。
今回はここまでということで。

